TOC
This post was translated from the Chinese version using Gemini 2.5 Pro.
Over the past two weeks, I’ve made two significant changes to RawWeb:
- Introduced SimHash for document deduplication.
- Migrated from Elasticsearch to Meilisearch to lower operational costs.
The implementation went smoothly. I successfully migrated and cleaned up 56k similar documents, but I also ran into some memory and performance challenges with Meilisearch.
Document Deduplication
Previously, I simply used URLs as the unique constraint, which often led to discovering a large number of duplicate documents during maintenance.
Common reasons for duplication:
- Non-standardized URLs
- Inconsistent case sensitivity
- Inconsistent trailing slashes
- Useless query parameters
- Different number or order of query parameters
- A single blog having multiple domains
- Blogs changing their path structure, e.g., from
/blog/1to/posts/1
URL-based deduplication is simple to implement but has significant limitations and can’t cover all edge cases. To solve the duplication problem fundamentally, we need to work with the content itself.
SimHash
SimHash is a locality-sensitive hashing algorithm. It reflects the features of different parts of a text and allows for efficient similarity assessment using the Hamming distance.
For example, consider the following two strings. Their SimHash values differ by only a few bits, while their md5 hashes are completely different.
| data | simhash | md5 |
|---|---|---|
| i think a is the best | 10000110110000000000000000101001 | 846ff6bebe901ead008e9c0e01a87470 |
| i think b is the best | 10000010110000000000100001101010 | ba1d2dc00d0a23dbb2001d570f03fb19 |
Compared to other text similarity calculation methods, Simhash’s advantages are its lightweight computation, storage, and comparison. It also has a strong endorsement: Google’s web crawler uses SimHash to identify duplicate web pages.
Calculating Hash and Hamming Distance
Implementing SimHash is simple. I relied entirely on Claude Sonnet 3.5 to implement the basic SimHash and Hamming distance calculations, then used test cases to evaluate the results.
Key points:
- Use a 64-bit hash value. This is a balanced length.
- Use the fnv hash algorithm. It’s simple, efficient, and distributes well.
- Split the hash value into four 16-bit segments for database storage. This provides more flexibility when comparing Hamming distances.
package simhash
import (
"backend/core/pkgs/simhash/tokenizer"
"hash/fnv"
)
const (
// HASH_BITS represents the number of bits in a SimHash value
HASH_BITS = 64
)
// CalculateSimHash calculates the SimHash value of a text
// SimHash is a hashing algorithm used for calculating text similarity, effectively detecting the degree of similarity between texts
// Algorithm steps:
// 1. Tokenize the text
// 2. Calculate the hash value for each token
// 3. Merge all token hash values into a feature vector
// 4. Derive the final SimHash value from the feature vector
func CalculateSimHash(text string) uint64 {
if text == "" {
return 0
}
words := tokenizer.Tokenize(text)
weights := make([]int, HASH_BITS)
// Calculate hash for each token and update weights
for _, word := range words {
hash := getHash(word)
// Update weights based on each bit position
for i := 0; i < HASH_BITS; i++ {
if (hash & (1 << uint(i))) != 0 {
weights[i]++
} else {
weights[i]--
}
}
}
// Generate the final simhash value
var simhash uint64
for i := 0; i < HASH_BITS; i++ {
if weights[i] > 0 {
simhash |= (1 << uint(i))
}
}
return simhash
}
// getHash calculates the hash value of a string
func getHash(s string) uint64 {
h := fnv.New64a()
h.Write([]byte(s))
return h.Sum64()
}
// HammingDistance calculates the Hamming distance between two simhash values
// Hamming distance is the number of different characters at corresponding positions in two equal-length strings
// In SimHash, a smaller Hamming distance indicates higher similarity between two texts
func HammingDistance(hash1, hash2 uint64) int {
xor := hash1 ^ hash2
distance := 0
// Count the number of different bits (Brian Kernighan algorithm, better performance)
for xor != 0 {
distance++
xor &= xor - 1
}
return distance
}
// SplitSimHash splits a simhash value into four 16-bit parts
func SplitSimHash(hash uint64) [4]uint16 {
return [4]uint16{
uint16((hash >> 48) & 0xFFFF),
uint16((hash >> 32) & 0xFFFF),
uint16((hash >> 16) & 0xFFFF),
uint16(hash & 0xFFFF),
}
}
// MergeSimHash merges four 16-bit parts into a single simhash value
func MergeSimHash(parts [4]uint16) uint64 {
return (uint64(parts[0]) << 48) | (uint64(parts[1]) << 32) | (uint64(parts[2]) << 16) | uint64(parts[3])
}
// IsSimilar determines whether two texts are similar
// threshold represents the similarity threshold, typically a value between 3-10
// Returns true if the two texts are similar, false if not
func IsSimilar(hash1, hash2 uint64, threshold int) bool {
return HammingDistance(hash1, hash2) <= threshold
}# pgsql
CREATE OR REPLACE FUNCTION hamming_distance(
simhash1_1 SMALLINT,
simhash1_2 SMALLINT,
simhash1_3 SMALLINT,
simhash1_4 SMALLINT,
simhash2_1 SMALLINT,
simhash2_2 SMALLINT,
simhash2_3 SMALLINT,
simhash2_4 SMALLINT
) RETURNS INTEGER
PARALLEL SAFE
AS $$
BEGIN
RETURN bit_count((simhash1_1 # simhash2_1)::BIT(16)) +
bit_count((simhash1_2 # simhash2_2)::BIT(16)) +
bit_count((simhash1_3 # simhash2_3)::BIT(16)) +
bit_count((simhash1_4 # simhash2_4)::BIT(16));
END;
$$ LANGUAGE plpgsql IMMUTABLE;Further Optimizing Tokenization
The tokens generated by the tokenizer are the basic units for calculating SimHash. The higher the quality of tokenization, the more accurately SimHash can reflect the document’s features.
I tested several types of tokenizers:
- Based on language features
- Whitespace: Suitable for languages like English that use spaces as separators, but requires additional implementation for normalization, stopword removal, etc.
- Unicode: Intended as a tokenizer for CJK languages, but the tokenization quality was not ideal.
- N-gram: Considered as a general-purpose tokenizer, but the quality fluctuates significantly.
Overall, Charabia produced the best results. However, it’s a Rust project, while the RawWeb backend stack is Go. This requires using CGO to call Charabia (calling via Go’s exec package is at least 10x slower than calling via CGO), which introduces cross-compilation complexity.
I’m not familiar with Rust or CGO, so most of the following code was generated by Claude Sonnet 3.5/3.7, with some adjustments based on the actual situation.
First, expose Charabia’s Tokenize method with a simple Rust function:
use charabia::Tokenize;
use libc::{c_char};
use serde_json::json;
use std::ffi::{CStr, CString};
use std::ptr;
fn tokenize_string(input: &str) -> Vec<String> {
input
.tokenize()
.filter(|token| token.is_word())
.map(|token| token.lemma().to_string().trim().to_string())
.filter(|token| !token.is_empty())
.collect()
}
/// Tokenizes the input string and returns a JSON string containing the tokens
///
/// # Safety
///
/// This function is unsafe because it deals with raw pointers
#[no_mangle]
pub unsafe extern "C" fn tokenize(input: *const c_char) -> *mut c_char {
// C stuff ...
// Tokenize the input
let tokens = tokenize_string(input_str);
// C stuff ...Cargo.toml:
# ...
[lib]
name = "charabia_rs"
crate-type = ["cdylib", "staticlib"]
[dependencies]
charabia = { version = "0.9.3", default-features = false, features = [
"chinese-segmentation", # disable chinese-normalization (https://github.com/meilisearch/charabia/issues/331)
#"german-segmentation",
"japanese",
] }
# ...For local testing, just run cargo build --release. But cross-platform compilation is much more complicated. Fortunately, the Zig toolchain greatly simplifies C cross-compilation, eliminating the need for musl libc!
Install Zig and zigbuild, then compile:
cargo zigbuild --release --target aarch64-unknown-linux-gnuAfter compiling the Rust code into a .so file, call its exported method in RawWeb. Need to configure linking to the correct .so during cross-compilation and loading the .so file from ./lib when the application starts online:
// #cgo linux,amd64 LDFLAGS: -L${SRCDIR}/charabia-rs/target/x86_64-unknown-linux-gnu/release -lcharabia_rs -Wl,-rpath,./lib
// #cgo linux,arm64 LDFLAGS: -L${SRCDIR}/charabia-rs/target/aarch64-unknown-linux-gnu/release -lcharabia_rs -Wl,-rpath,./lib
// #cgo LDFLAGS: -L${SRCDIR}/charabia-rs/target/release -lcharabia_rs
// #include <stdlib.h>
// #include <stdint.h>
//
// typedef void* charabia_result_t;
//
// extern char* tokenize(const char* input);
// extern void free_tokenize_result(char* ptr);
import "C"
// Tokenize tokenizes the given text using the Rust implementation via cgo
func Tokenize(text string) []string {
// C stuff ...
cResult := C.tokenize(cText)
// C stuff ...Also using Zig for cross-compiling the Go code:
CGO_ENABLED=1 GOOS=linux GOARCH=arm64 CC="zig cc -target aarch64-linux" CXX="zig c++ -target aarch64-linux" go build ...Finally, during deployment, place libcharabia_rs.so into the ./lib/ directory so it can be loaded.
Filtering Similar Content
According to resources, a Hamming distance of less than 3 for a 64-bit SimHash can generally identify similar content.
However, due to limitations in tokenization quality, content length, etc., I observed false positives even with a Hamming distance threshold of 1 in my test cases. Additionally, my server has low specs. Calculating and comparing the Hamming distance for one document against 700k records takes about 1.2 seconds. At this rate, a full comparison would take 10 days, which is unacceptable.
Therefore, for now, I only filtered documents with identical hash values. This avoids calculating Hamming distance and allows the search to use database indexes, making it very fast. Ultimately, I cleaned up 56,000 similar documents. This number was much higher than I expected. Given that I encountered SimHash collisions during testing, I reasonably suspect there might be quite a few false positives among them. Further optimization of tokenization and token weighting is needed.
References
- Near-Duplicate Detection
- SimHash and solving the hamming distance problem: explained
- Detecting Near-Duplicates for Web Crawling - Google Research
Migrating to Meilisearch
The full-text search engine I previously used was Elasticsearch. It’s feature-rich and battle-tested in countless production environments.
As RawWeb’s features and data volume stabilized, I realized I wasn’t using most of Elasticsearch’s capabilities, yet I still had to bear the extra operational costs (actually, it had been very stable since deployment, but if such a behemoth encountered problems one day, I wasn’t sure if I had the ability or energy to fix them). Also, the elasticsearch-go client is very difficult to use.
Meilisearch is a more lightweight alternative, with most features working out of the box. The migration process was very smooth, although a few unexpected issues popped up.
Multilingual Documents
Referencing W3Techs’ statistics on content languages on the internet, RawWeb specifically tags content in English, Chinese, German, French, Spanish, Russian, and Japanese to enable filtering search results by language.
In Elasticsearch, I used separate fields like content_en, content_zh, etc., with dedicated tokenizers. Theoretically, this step could be simplified in Meilisearch because it can automatically detect content language. However, I ended up splitting the content into multiple indexes because:
- RawWeb’s existing natural language detection module can automatically sample based on document title and content length, switching precision modes automatically, which is more efficient than full-text detection.
- To filter search results by language, I need to add a
langfield in Meilisearch to mark the document’s language. So, besides Meilisearch, I still need to perform natural language detection once.
Splitting different languages into separate indexes also aligns with Meilisearch’s official recommendations.
Issue 1: High Storage Space Usage
The PostgreSQL database size is about 2.4GB. After importing documents, the Meilisearch database size grew to about 23GB (with searchableAttributes and filterableAttributes configured correctly).
Initially, I didn’t realize the implication about disk usage mentioned in the documentation, which led to the hard drive filling up. Fortunately, hard drive space is the cheapest cloud resource, so expanding it wasn’t expensive.
Besides this, there’s another potential issue: Meilisearch doesn’t release disk space after deleting documents (docs). Reclaiming space might require using snapshots (related discussion).
Issue 2: Memory Usage Limit Ineffective
Meilisearch is deployed on a low-spec server with 2 vCPUs and 4GB RAM. Since Elasticsearch previously ran fine on a server with the same configuration, I assumed Meilisearch would be smooth sailing too. After indexing all documents, I went to sleep peacefully (I later realized they were probably just queued in Meilisearch’s task queue at that time).
I woke up to find the server’s CPU maxed out and disk read speeds exceeding 1GB/s, causing the entire system to freeze. After a forced reboot, I checked the system logs and the only abnormality found was an OOM error from the Meilisearch container. I then used MEILI_MAX_INDEXING_MEMORY to limit indexing memory usage to 2GB. However, the next day, it experienced OOM and maxed-out CPU again.
Looking through the documentation, I found the MEILI_EXPERIMENTAL_REDUCE_INDEXING_MEMORY_USAGE parameter. Although experimental, I tried it and found it worked really well. CPU and disk I/O were no longer aggressive.
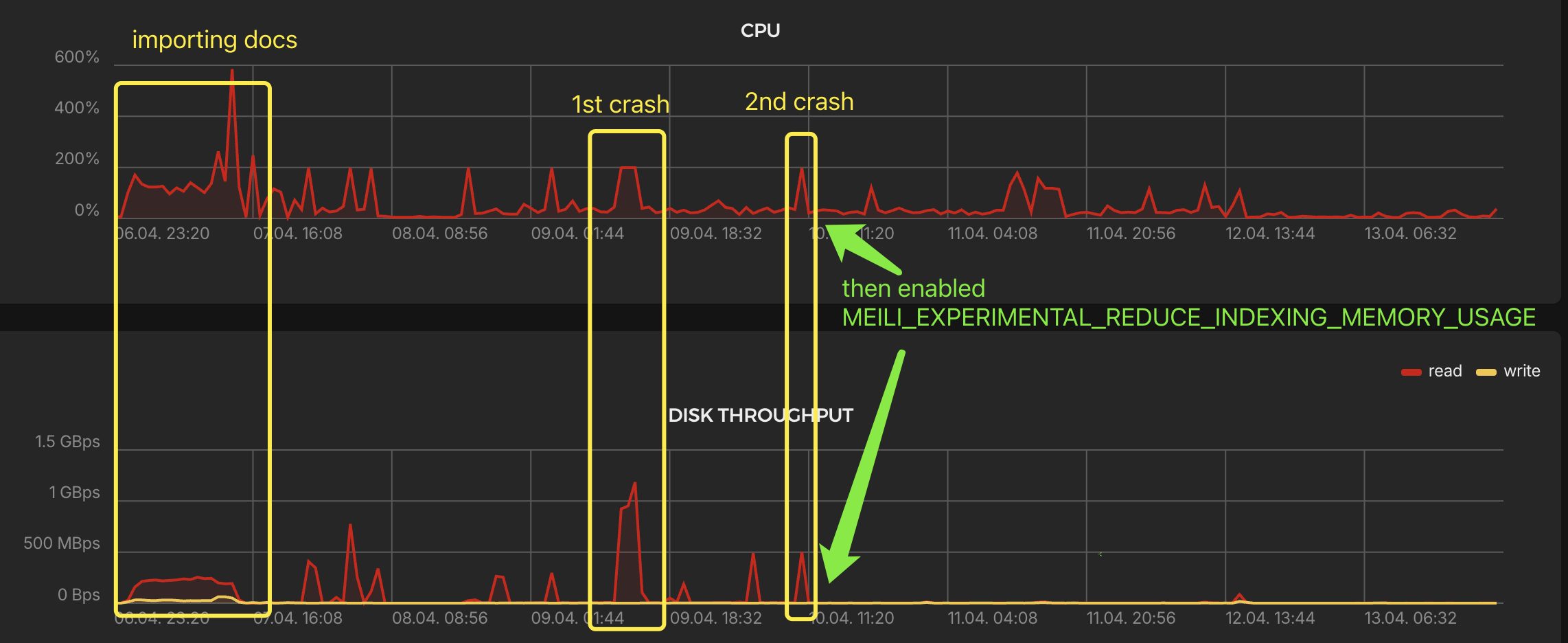
Issue 3: Very Slow Document Deletion Leading to Task Backlog
To clean up documents in Meilisearch that were deleted from the database, the operation for each batch during synchronization was:
- Delete documents in Meilisearch within the range
id >= ? AND id <= ?. - Add new documents.
After deploying, data synchronization ran into problems. Investigation revealed that Meilisearch had accumulated 133k tasks:
//GET /tasks?statuses=enqueued,processing
{"results":[{"uid":16354,"batchUid":null,"indexUid":"items_es","status":"enqueued","type":"documentAdditionOrUpdate","canceledBy":null,"details":{"receivedDocuments":7,"indexedDocuments":null},"error":null,"duration":null,"enqueuedAt":"2025-04-12T04:59:27.183657254Z","startedAt":null,"finishedAt":null},...],"total":13385,"limit":20,"from":16354,"next":16334}Observing task execution, I found that document deletion operations were extremely slow. A range deletion involving up to 1,000 documents took nearly 20 minutes. Furthermore, because deletion and addition operations were interspersed during synchronization, Meilisearch couldn’t automatically merge adjacent tasks.
I couldn’t find similar issues online; this seems to be a problem unique to my setup. I suspect it’s because of the limited memory and the fact that Hetzner’s expanded storage performance is only 1/10th of the original disk performance (benchmark). I’ll retest this once I get sponsorship funds to upgrade to a higher-spec server.
Conclusion
The main goals of this update have been achieved. I will continue debugging and optimizing.
Additionally, the implementation process exposed some operational issues, such as excessive downtime and lack of server resource alerts (I removed New Relic monitoring during the last refactor). These will be targets for the next round of optimization.