TOC
最近半个月给 RawWeb 添加了两个重要变动:
- 引入 SimHash 实现文档去重
- 从 Elasticsearch 迁移到 Meilisearch,降低运维成本
实施过程比较顺利,最终成功迁移并清理了 56k 个相似文档,但也遇到了 Meilisearch 内存和性能上的一些挑战。
文档去重
早先简单地使用 URL 作为唯一性约束,这导致在维护时经常发现大量文档内容重复。
常见的重复原因:
- URL 不规范
- 路径大小写不一致
- 路径尾部斜杠不一致
- 存在无用的查询参数
- 查询参数数量、顺序不同
- 一个博客有多个域名
- 博客修改了路径规则,比如从
/blog/1变为了/posts/1
基于 URL 的去重实现简单,但总归有很大的局限性,且无法涵盖所有异常情况。要想从根上解决重复问题,还得从内容本身下手。
SimHash
SimHash 是一种局部敏感的哈希算法,能够体现文本各部分的特征,并且可以通过汉明距离来高效地评估相似度。
比如如下两个字符串,SimHash 只有几个 bit 的差别,而 md5 则完全不同。
| data | simhash | md5 |
|---|---|---|
| i think a is the best | 10000110110000000000000000101001 | 846ff6bebe901ead008e9c0e01a87470 |
| i think b is the best | 10000010110000000000100001101010 | ba1d2dc00d0a23dbb2001d570f03fb19 |
相较于其他文本相似度计算方法,Simhash 的优点在于计算、存储、比较都非常轻量,并且有强力背书:Google 爬虫使用 SimHash 识别重复网页。
计算哈希和汉明距离
实现 SimHash 比较简单,完全依靠 Claude Sonnet 3.5 实现了基本的 SimHash 和汉明距离计算,然后用测试用例评估效果。
几个关键点:
- 使用 64 bits 哈希值。这是一个比较均衡的长度
- 使用 fnv 哈希算法。简单高效、散列均匀
- 将哈希值拆分为 4 段 16 bits 存入数据库,可以在比较汉明距离时提供更高的灵活性
package simhash
import (
"backend/core/pkgs/simhash/tokenizer"
"hash/fnv"
)
const (
// HASH_BITS represents the number of bits in a SimHash value
HASH_BITS = 64
)
// CalculateSimHash calculates the SimHash value of a text
// SimHash is a hashing algorithm used for calculating text similarity, effectively detecting the degree of similarity between texts
// Algorithm steps:
// 1. Tokenize the text
// 2. Calculate the hash value for each token
// 3. Merge all token hash values into a feature vector
// 4. Derive the final SimHash value from the feature vector
func CalculateSimHash(text string) uint64 {
if text == "" {
return 0
}
words := tokenizer.Tokenize(text)
weights := make([]int, HASH_BITS)
// Calculate hash for each token and update weights
for _, word := range words {
hash := getHash(word)
// Update weights based on each bit position
for i := 0; i < HASH_BITS; i++ {
if (hash & (1 << uint(i))) != 0 {
weights[i]++
} else {
weights[i]--
}
}
}
// Generate the final simhash value
var simhash uint64
for i := 0; i < HASH_BITS; i++ {
if weights[i] > 0 {
simhash |= (1 << uint(i))
}
}
return simhash
}
// getHash calculates the hash value of a string
func getHash(s string) uint64 {
h := fnv.New64a()
h.Write([]byte(s))
return h.Sum64()
}
// HammingDistance calculates the Hamming distance between two simhash values
// Hamming distance is the number of different characters at corresponding positions in two equal-length strings
// In SimHash, a smaller Hamming distance indicates higher similarity between two texts
func HammingDistance(hash1, hash2 uint64) int {
xor := hash1 ^ hash2
distance := 0
// Count the number of different bits (Brian Kernighan algorithm, better performance)
for xor != 0 {
distance++
xor &= xor - 1
}
return distance
}
// SplitSimHash splits a simhash value into four 16-bit parts
func SplitSimHash(hash uint64) [4]uint16 {
return [4]uint16{
uint16((hash >> 48) & 0xFFFF),
uint16((hash >> 32) & 0xFFFF),
uint16((hash >> 16) & 0xFFFF),
uint16(hash & 0xFFFF),
}
}
// MergeSimHash merges four 16-bit parts into a single simhash value
func MergeSimHash(parts [4]uint16) uint64 {
return (uint64(parts[0]) << 48) | (uint64(parts[1]) << 32) | (uint64(parts[2]) << 16) | uint64(parts[3])
}
// IsSimilar determines whether two texts are similar
// threshold represents the similarity threshold, typically a value between 3-10
// Returns true if the two texts are similar, false if not
func IsSimilar(hash1, hash2 uint64, threshold int) bool {
return HammingDistance(hash1, hash2) <= threshold
}# pgsql
CREATE OR REPLACE FUNCTION hamming_distance(
simhash1_1 SMALLINT,
simhash1_2 SMALLINT,
simhash1_3 SMALLINT,
simhash1_4 SMALLINT,
simhash2_1 SMALLINT,
simhash2_2 SMALLINT,
simhash2_3 SMALLINT,
simhash2_4 SMALLINT
) RETURNS INTEGER
PARALLEL SAFE
AS $$
BEGIN
RETURN bit_count((simhash1_1 # simhash2_1)::BIT(16)) +
bit_count((simhash1_2 # simhash2_2)::BIT(16)) +
bit_count((simhash1_3 # simhash2_3)::BIT(16)) +
bit_count((simhash1_4 # simhash2_4)::BIT(16));
END;
$$ LANGUAGE plpgsql IMMUTABLE;进一步优化分词
分词得到的 token 是计算 SimHash 时的基本单元,分词的质量越高,SimHash 越能精确反映文档特征。
测试了几类分词器:
- 基于语言特性
- 空格:适合英文等以空格分隔的语言,但是也需要额外实现规范化、去除 stopword 等
- Unicode:想用来作为 CJK 等语言的分词器,但分词质量不理想
- N-gram:想用来作为通用的分词器,但分词质量的波动比较大
综合来看 Charabia 的效果是最好的。但这是一个 Rust 项目,而 RawWeb 服务端技术栈是 Go,需要 CGO 来调用 Charabia (Go 调用 cli 的方式比 CGO 调用的性能差至少 10 倍),这又引入了交叉编译的复杂性。
我不会 Rust 和 CGO,以下代码大都都由 Claude Sonnet 3.5/3.7 生成,结合实际情况做了些调整。
首先用一个简单的 Rust 函数暴露 Charabia 的 Tokenize 方法:
use charabia::Tokenize;
use libc::{c_char};
use serde_json::json;
use std::ffi::{CStr, CString};
use std::ptr;
fn tokenize_string(input: &str) -> Vec<String> {
input
.tokenize()
.filter(|token| token.is_word())
.map(|token| token.lemma().to_string().trim().to_string())
.filter(|token| !token.is_empty())
.collect()
}
/// Tokenizes the input string and returns a JSON string containing the tokens
///
/// # Safety
///
/// This function is unsafe because it deals with raw pointers
#[no_mangle]
pub unsafe extern "C" fn tokenize(input: *const c_char) -> *mut c_char {
// C stuff ...
// Tokenize the input
let tokens = tokenize_string(input_str);
// C stuff ...Cargo.toml:
# ...
[lib]
name = "charabia_rs"
crate-type = ["cdylib", "staticlib"]
[dependencies]
charabia = { version = "0.9.3", default-features = false, features = [
"chinese-segmentation", # disable chinese-normalization (https://github.com/meilisearch/charabia/issues/331)
#"german-segmentation",
"japanese",
] }
# ...本机测试时可以直接运行 cargo build --release 编译,但跨平台编译麻烦很多。幸运地是 Zig 的工具链极大降低了交叉编译 C 的难度,不需要再借助 musl libc 了!
安装 Zig 和 zigbuild,然后编译:
cargo zigbuild --release --target aarch64-unknown-linux-gnu将 Rust 代码编译成 .so 后,在 RawWeb 中调用其导出的方法。要配置交叉编译时链接正确的 .so、线上程序启动时从 ./lib 加载 .so:
// #cgo linux,amd64 LDFLAGS: -L${SRCDIR}/charabia-rs/target/x86_64-unknown-linux-gnu/release -lcharabia_rs -Wl,-rpath,./lib
// #cgo linux,arm64 LDFLAGS: -L${SRCDIR}/charabia-rs/target/aarch64-unknown-linux-gnu/release -lcharabia_rs -Wl,-rpath,./lib
// #cgo LDFLAGS: -L${SRCDIR}/charabia-rs/target/release -lcharabia_rs
// #include <stdlib.h>
// #include <stdint.h>
//
// typedef void* charabia_result_t;
//
// extern char* tokenize(const char* input);
// extern void free_tokenize_result(char* ptr);
import "C"
// Tokenize tokenizes the given text using the Rust implementation via cgo
func Tokenize(text string) []string {
// C stuff ...
cResult := C.tokenize(cText)
// C stuff ...同样借助 Zig 来交叉编译:
CGO_ENABLED=1 GOOS=linux GOARCH=arm64 CC="zig cc -target aarch64-linux" CXX="zig c++ -target aarch64-linux" go build ...最后部署时将 libcharabia_rs.so 放到 ./lib/ 中即可被加载。
筛选相似内容
根据资料,对于 64 位的 SimHash 来说汉明距离小于 3 就可以判定为相似。
但受限于分词质量、内容长度等因素,在我的测试用例中设置汉明距离为 1 也会出现误判。另外 VPS 配置太低,在 700k 条数据中为一个文档计算并比较汉明距离耗时 1.2s 左右,算下来全量比较一次需要 10 天。这显然不可接受。
所以暂时只筛选了哈希值完全相同的文档,这样无需计算汉明距离,搜索能够使用数据库索引,速度非常快。最终清理了 56k 个相似文档,这个数量远超我的预估,鉴于测试时出现过 SimHash 碰撞,合理怀疑这其中有不少误伤。后续还得优化分词和 token 权重。
参考
- Near-Duplicate Detection
- SimHash and solving the hamming distance problem: explained
- Detecting Near-Duplicates for Web Crawling - Google Research
迁移到 Meilisearch
先前使用的全文搜索引擎是 Elasticsearch,功能丰富,经受了无数生产环境的检验。
随着 RawWeb 功能和数据量级趋于稳定,我发现 Elasticsearch 的大部分功能都用不上,但还要为此付出额外的运维成本(其实部署之后一直很稳定,但如果这么一个庞然大物哪天出现问题,我不确定是否有能力和精力去解决),而且 elasticsearch-go 非常难用。
Meilisearch 是一个更轻量级的替代方案,大部分功能都是开箱即用。迁移过程非常丝滑,不过也出现了几个意想不到的问题。
多语言文档
参考 W3Techs 互联网内容语言统计,RawWeb 特别标记了英语、中文、德语、法语、西班牙语、俄语、日语内容以实现按语言筛选搜索结果。
在 Elasticsearch 中分为了 content_en、content_zh 等字段并设置专用分词器,理论上在 Meilisearch 中可以简化掉这一步,因为 Meilisearch 能自动识别内容语言,但我最终还是拆分为了多个索引,因为:
- RawWeb 已有的自然语言识别模块能够根据文档标题和内容长度自动抽样,自动切换精度模式,相比全文识别效率更高
- 要实现根据语言过滤搜索结果,需要给在 Meilisearch 中添加一个
lang字段标记文档的语言,所以除了 Meilisearch 之外还得做一次自然语言识别
将不同语言拆分到单独的索引中也符合 Meilisearch 官方的建议。
问题 1. 存储空间占用大
PostgreSQL 数据库大小约 2.4GB,导入文档后 Meilisearch 数据库大小约 23GB (searchableAttributes 和 filterableAttributes 都已正确配置)。
最初我没意识到了文档中对于磁盘使用量的暗示,导致硬盘被写满。好在硬盘是最便宜的云服务资源,扩容起来并不贵。
除此之外还有一个潜在问题:删除文档后 Meilisearch 并不会释放磁盘空间(文档)。要释放空间的话可能要借助快照(相关讨论)。
问题 2. 内存使用量限制失效
Meilisearch 部署在一台 2 vCPU 4GB RAM 的低配服务器上,由于之前 Elasticsearch 部署在同样配置的服务器上且运行良好,所以我以为 Meilisearch 也会一切顺利,索引完全部文档后就安心睡觉了(后来意识到大概当时只是进入 Meilisearch 任务队列了)。
醒来发现服务器 CPU 满载且磁盘读速度超过 1GB/s,整个系统卡死。强制重启后检查系统日志,能发现的异常只有 Meilisearch 容器的 OOM。于是使用 MEILI_MAX_INDEXING_MEMORY 限制了索引时内存使用量为 2GB。但是第二天再次出现 OOM 且 CPU 满载。
翻文档发现了 MEILI_EXPERIMENTAL_REDUCE_INDEXING_MEMORY_USAGE 参数,虽然是实验性的,试了一下发现效果确实很好,CPU 和磁盘读写都不再激进了。
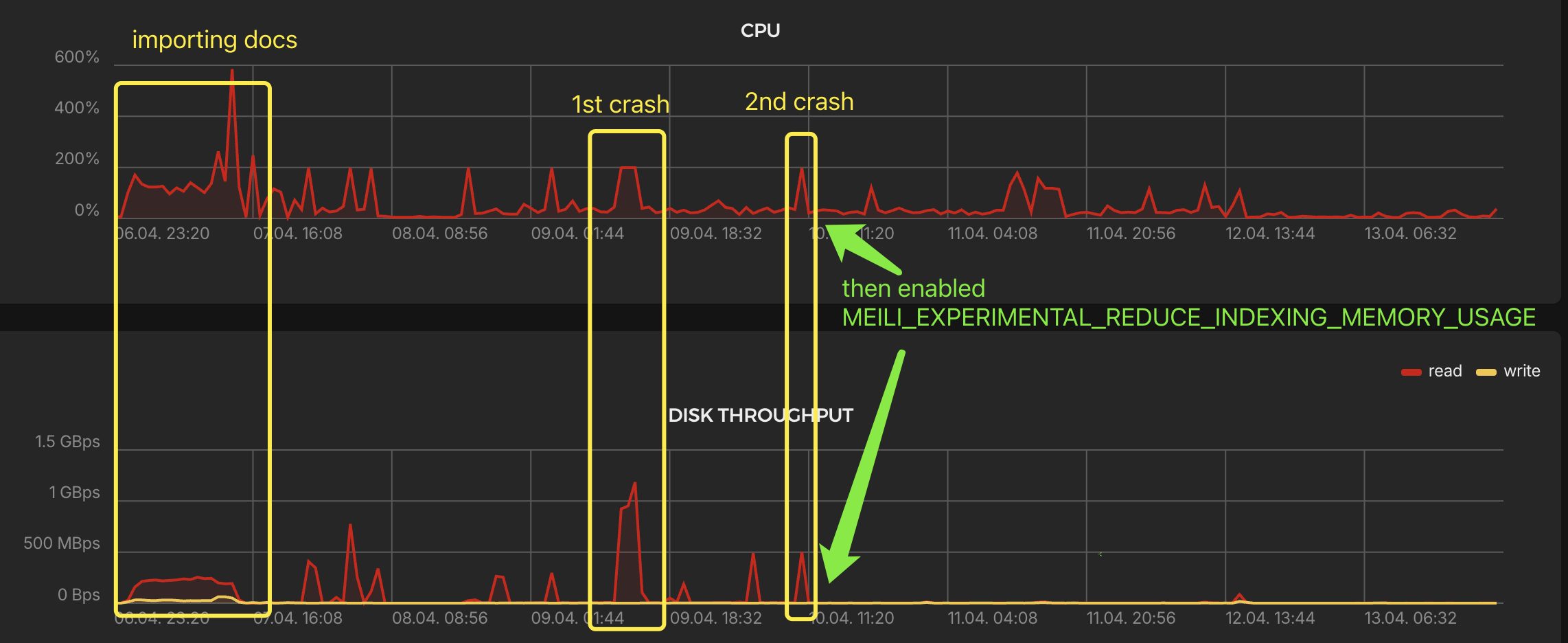
问题 3. 文档删除非常慢导致任务积压
为了给 Meilisearch 清理数据库中已被删除的文档,同步时每批文档的操作为:
- 在 Meilisearch 中按照
id >= ? AND id <= ?范围删除 - 新增文档
上线后数据同步出现问题,排查发现 Meilisearch 已经积压了 133k 个任务:
//GET /tasks?statuses=enqueued,processing
{"results":[{"uid":16354,"batchUid":null,"indexUid":"items_es","status":"enqueued","type":"documentAdditionOrUpdate","canceledBy":null,"details":{"receivedDocuments":7,"indexedDocuments":null},"error":null,"duration":null,"enqueuedAt":"2025-04-12T04:59:27.183657254Z","startedAt":null,"finishedAt":null},...],"total":13385,"limit":20,"from":16354,"next":16334}观察任务执行情况发现文档删除操作非常慢,一次最多涉及 1k 个文档的范围删除要花费接近 20 分钟,并且由于同步文档时穿插着删除和新增操作,导致 Meilisearch 无法自动合并相邻任务。
没有搜到相似的 issue,这似乎是我独有的问题。怀疑是因为内存太小,且 Hetzner 扩展硬盘的性能仅为原始硬盘的 1/10(benchmark)。等拉到赞助有钱换高配服务器了再重新测试。
总结
这次更新的主要目标都已达成,之后将持续调试优化。
另外在实施过程中暴露了一些运维问题,比如停机时间过长、缺少服务器资源告警(上次重构时移除了 New Relic 监控)等,作为下一轮优化的对象。