「SF」子域名搜集工具开发小结
SF 是一个 Golang 开发的高性能的子域名搜集工具,支持字典爆破等搜集方式。项目地址:github.com/0x2E/sf
开发过程中学习了很多文章(见文末),感谢师傅们的分享,于是我也把遇到的几个有意思的点整理了出来。
字典爆破
简易版
net 库提供的 lookup 系列函数不能指定 DNS 服务器,所以用了 miekg/dns,调用起来很简单:
func lookup(domain string, resolver string, retry int) string {
m := new(dns.Msg)
m.SetQuestion(domain, dns.TypeA) // 默认要求递归
var r *dns.Msg
var err error
for i := 0; i <= retry; i++ {
r, err = dns.Exchange(m, resolver) // 默认2秒超时
if err == nil {
break
}
}
if err != nil { // 重试之后仍有错误
fmt.Print("lookup error: " + domain + " - " + err.Error())
return ""
}
if r.Rcode != dns.RcodeSuccess || len(r.Answer) == 0 {
return ""
}
res := strings.Replace(r.Answer[0].String(), r.Answer[0].Header().String(), "", 1) // https://github.com/miekg/dns/issues/1204#issuecomment-751648288
fmt.Print(res)
return res
}当然,用起来简单是有代价的,dns.Exchange 发送 DNS 请求的过程经过了一次完整的 socket 生命周期(创建,发送,接收,关闭),会造成两个问题:
- 额外开销巨大
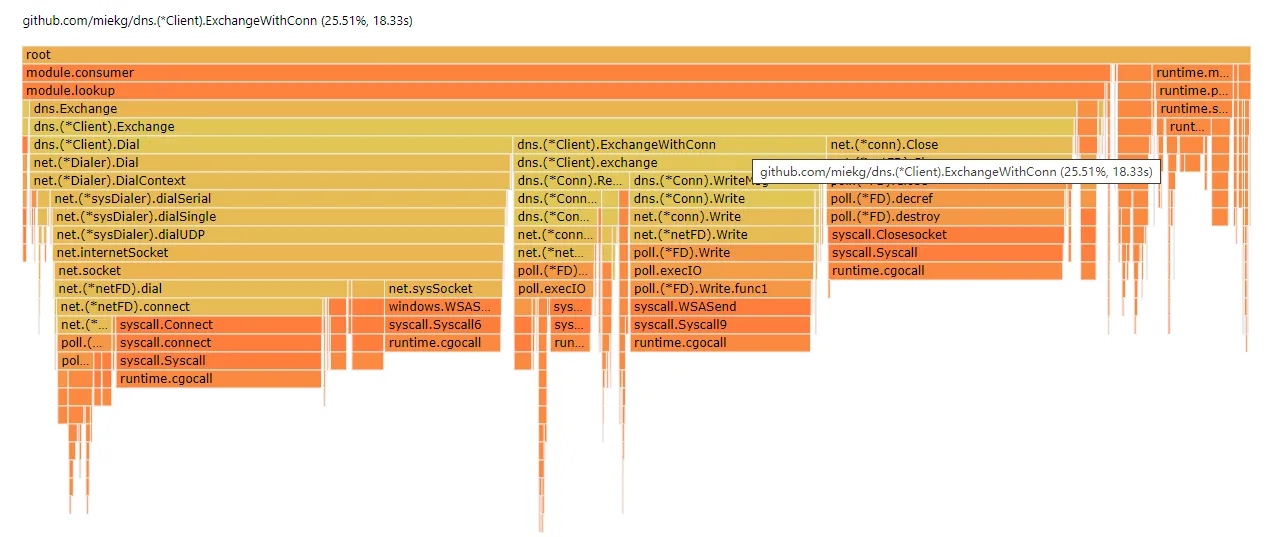
因为每次都要创建和关闭 socket,造成了大量的资源消耗,在火焰图上用于发送和接收的 dns.(*Client).ExchangeWithConn 的时间仅仅占 25.5%,创建 socket 的消耗几乎是读写的两倍。在测试过程中,开 2w 并发时 CPU 占有率基本维持在 50%,刚启动时甚至会在 90% 停留许久。
- 系统可用端口数不足
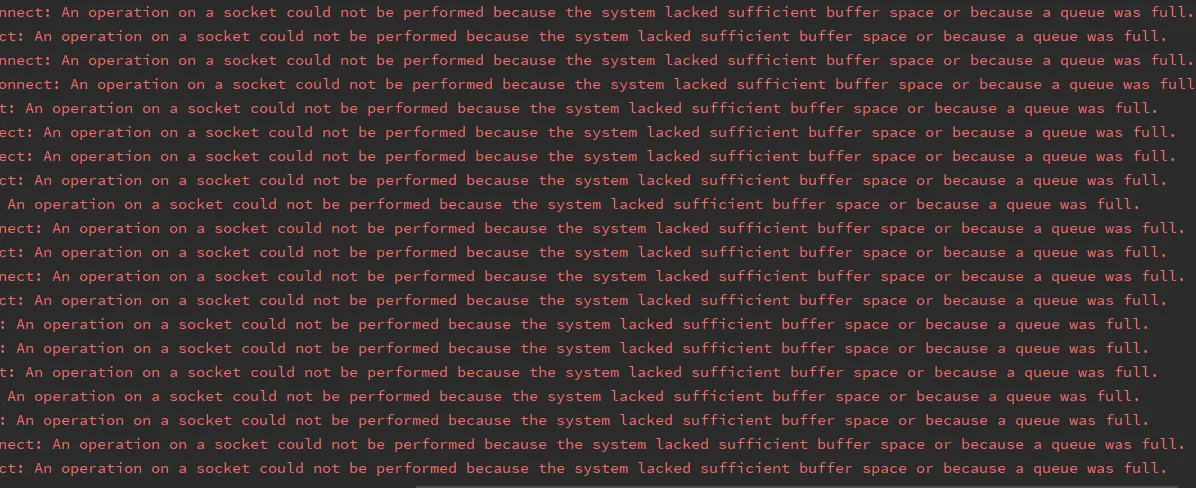
因为每个 socket 都是占用一个临时端口,如果并发开的太大可能撞上系统的最大临时端口数或最大文件打开数的限制,满屏的报错。(尝试从大于 5000 的 TCP 端口进行连接时 (错误”WSAENOBUFS) 10055) )
优化版
既然明确了问题出自 socket 的大量的创建/关闭操作,那么针对此进行优化:保持 socket 的开启状态,然后手动构造 DNS 报文并写入 UDP 包,持续发送,另开一个 goroutine 持续接收。
涉及到 DNS 报文的构造和解析,需要对 DNS 报文格式有初步了解,挺简单的,参考 Writing DNS messages from scratch using Go、Let’s hand write DNS messages 和 DNS 请求报文详解。第一篇文章中实现了一个库,我把其中需要的函数整理了一下(0x2E/rawdns)来更方便地构造和解析 DNS 报文:
package main
import (
"github.com/0x2E/rawdns"
"net"
)
func main() {
// create socket
conn, _ := net.Dial("udp", "8.8.8.8:53")
defer conn.Close()
// construct DNS packet content
payload, _ := rawdns.Marshal(33, 1, "github.com", rawdns.QTypeA)
// send UDP packet
_, _ = conn.Write(payload)
// receive UDP packet
buf := make([]byte, 0, 1024)
n, _ := conn.Read(buf)
// parse
resp, _ := rawdns.Unmarshal(buf[:n])
}为了防止发送过快但接收跟不上而冲爆缓存,还需设置一个任务队列来尽量同步发送和接收的速度。
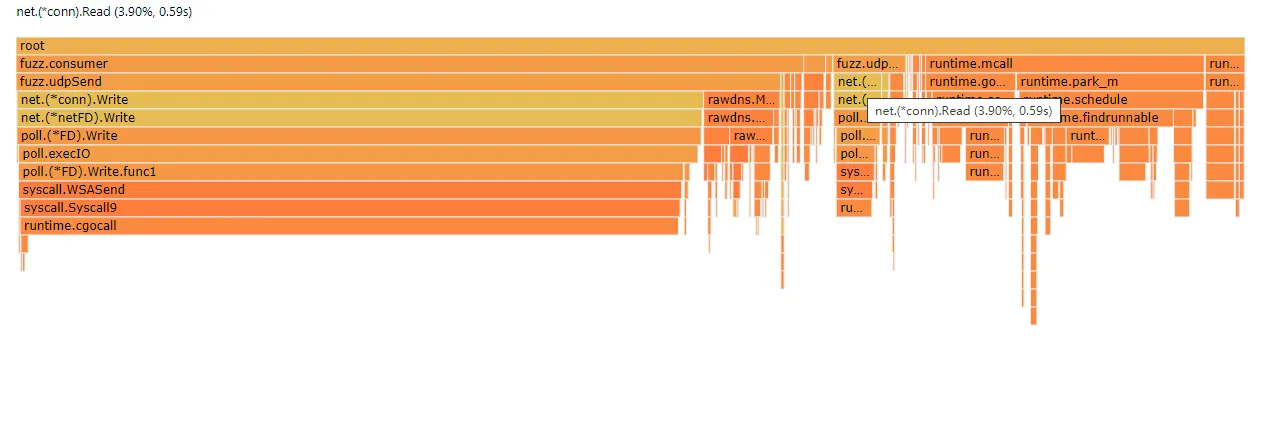
优化后效果显著,设队列大小为 200,使用 200 并发来爆破 10w 的字典用时 17 秒,与优化前基本相同,但 CPU 占用率降到了 15% 以内,火焰图中已经看不到 net.(*Dialer).Dial 的影子了。
泛解析
没有万全之策
目前的解决思路基本是:
- 通过查询随机生成的子域名,构造 IP 黑名单
- 权威服务器中泛解析有相同 TTL
- 比较 DNS 响应的相似度
- 比较网页的相似度
即便不考虑性能问题,使用「匹配 IP 黑名单 ⇒ 比较 TTL ⇒ 比较 DNS 响应相似度 ⇒ 比较网页相似度」这一整套检测流程,看似全面,实则 naive,试想这种情况下还能否准确识别:某企业将部分域名泛解析到多台反向代理,再由反代根据域名转发到具体业务应用上,业务应用还会先检查登录状态以跳转到统一登录页。
如 FEEI 师傅的枚举子域名文中所说:
目前最好的解决方式是通过先获取一个绝对不存在域名的响应内容,再遍历获取每个字典对应的子域名的响应内容,通过和不存在域名的内容做相似度比对,来枚举子域名,但这样的实现是以牺牲速度为代价。 但这样还是存在问题,比如蘑菇街的商家是有自定义子域名功能的,他可以配置 sports.mogujie.com 为他的店铺域名,而所有店铺的响应内容是相似的。 这样就会导致虽然这些店铺域名和不存在的域名的响应内容不相似,但在最终的域名集合中有非常多的店铺自定义域名,这些域名对于漏洞扫描来说只需要有一个即可。 若再次对所有子域名进行响应相似度比对的话,又会出现新的问题,部分系统设计时,如果未登录可能跳统一登录页,会导致大量误杀。
尽力优化
SF 的泛解析处理分为两种模式:
- 宽松模式:仅匹配 IP 黑名单
- 严格模式:匹配 IP 黑名单 ⇒ 比较网页标题相似度。若无法访问 80 端口,则退化为宽松模式
本地测试了一下计算字符串相似度时,字符串的长度会引起耗时呈 3 倍左右增加。鉴于标题的作用即是概述网页主体的内容,所以这里选用了标题进行相似度比较。
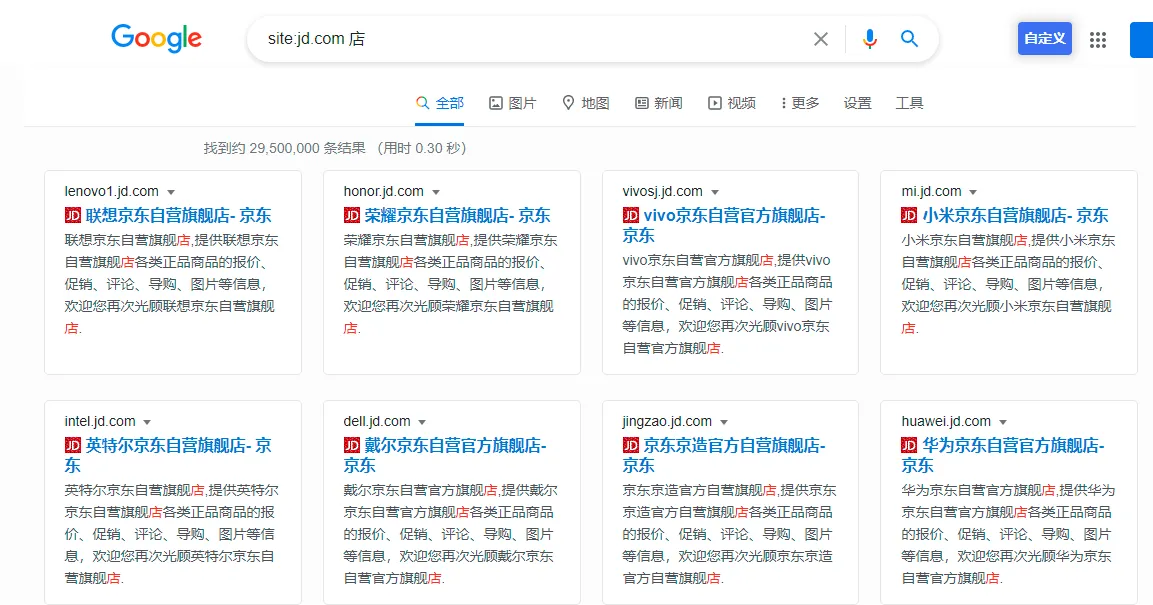
这是基于域名主体会严格限制标题格式的前提下,如京东等网店子域名(下图)。如果要问「那爆破 github.io 这类服务的子域名怎么办」,你爆破 github.io 干什么?
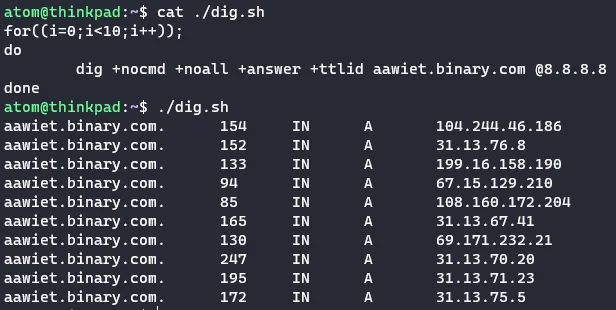
另外,可以看到两种模式都没有使用 TTL 参与匹配,因为其在非权威服务器上是持续衰减的,不能作为比较条件,所以还需要向权威服务器查询该域名的 TTL。在用百万大字典爆破泛解析大站时,会产生巨大的额外任务量,还有可能被权威服务器当作 DDos 而关进小黑屋。这仅仅为了甄别正常解析到了与泛解析相同 IP 的情况,性价比太低。甚至还有下图这种把所有不存在域名都随机返回一个无效 IP 的带恶人,测了一下大概有 580 个无效 IP 轮换使用,不知道是用了谁家的防护。
遗留问题
- 某些情况下无法获取网页标题
获取标题处使用的是 http.Get 函数获取网页 HTML 然后正则匹配出标题,很明显这无法适用于 SPA 网站,另外虽然可以跟随 301 等跳转,但无法根据 HTML 标签跳转,如百度:
<html>
<meta http-equiv="refresh" content="0;url=http://www.baidu.com/" />
</html>- 无法处理跳转到类似「统一登录页」的情况
可能的解决方法:从 url 中搜索类似 returnUrl 之类的参数,或者正则匹配 IP/url 以找到登陆后跳转的页面。那么新的问题又来了,有的网站会将链接进行特殊编码,如何解码呢。
缺少重试机制(2021.3.22 更新:906ec18 已完成)
爆破的结果不够稳定,初步判断是链路上会丢包,设置重试机制应该能解决问题。不想在内存设置一个状态表,担心会产生大量 lock/unlock,所以暂时没想好该怎么设计。
输出内容不清晰
在终端中的输出内容较少、不清晰,不利于使用时的排错,需要重写 logger 模块。缺少进度条。